상권 변화 분석
By 김가영, 장정윤
분석 목적
2020년, covid-19라는 바이러스가 유입되어 지금까지도 사람들은 불편한 생활을 겪고 있다. 코로나 이후 시대를 뉴노멀이라고 부를 만큼 우리들의 삶은 코로나바이러스로 인해 많은 점이 달라졌다. 그 중 코로나가 창궐하기 전인 2019년과 코로나 발생 후인 2020년에 상권은 이러한 시대 흐름에 따라 어떻게 변화하였는지 알아보고자 이 프로젝트를 하게 되었다. 더해서 업종 분류에 따른 결과의 차이를 알아보고자 두 종류의 결과를 비교해보고자 한다.
이 프로젝트의 목표는 공공데이터 상권분석데이터를 통한 머신러닝으로 상권의 축소와 확장을 예측하고 2019와 2020의 차이를 분석하는 것이다.
1. 데이터 전처리
2020년과 2019년을 비교분석하는데 앞서 2020년은 4분기의 자료가 없고 3분기 자료까지만 있어 2019년도 똑같이 반영하여 4분기 자료는 제거하였다. 변수는 총 9개(총 유동인구 수, 당월 매출 금액, 당월 매출 건수, 점포 수, 개업 점포 수, 폐업 점포 수, 집객 시설 수, 총 직장인구 수, 아파트 단지 수)와 target 변수인 상권 변화 지표를 선택했다. 상권 변화 지표는 hl(상권축소), hh(정체), lh(상권확장), ll(다이나믹) 등이었는데 이를 1(확장,다이나믹,정체), 0(축소)로 매핑했다.
1.1. 업종 분류(김가영)
같은 상권이더라도 업종이 다르다면 다른 데이터로 분류해주었다.
1.1.1. 전처리 전
-코로나 이전(2019)
-코로나 이후(2020)
1.1.2. 상관관계 분석(R)
-코로나 이전(2019)
-코로나 이후(2020)
1.2. 업종 통합(장정윤)
같은 상권이라면 업종별로 나누지 않고 전처리하였다.
1.2.1. 전처리 전
-코로나 이전(2019)
-코로나 이후(2020)
1.2.2. 상관관계 분석(R)
-코로나 이전(2019)
-코로나 이후(2020)
2. 데이터 시각화
머신러닝을 돌려보기 전 각 변수들의 분포를 알아보고자 타겟에 대한 변수별 그래프를 그려보았다. 0은 축소, 1은 확장, 다이나믹, 정체이다.
2.1. 업종 분류(김가영)
2.1.1. 기준 분기별 그래프
-코로나 이전(2019)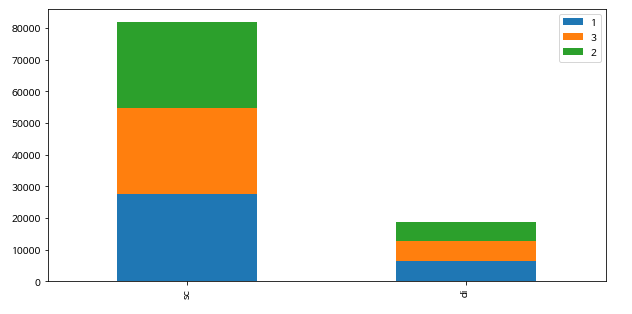
-코로나 이후(2020)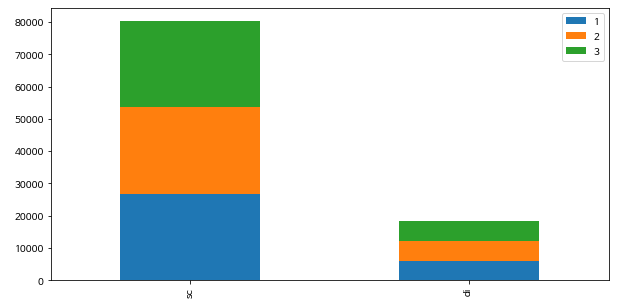
분기는 계절에 따른 변동을 포함할 수도 있는 자료이기 때문에, 변수에 포함할지에 대한 의사결정이 필요했습니다. 이에 그래프를 통해 경향성을 파악하고 결과에 큰 영향을 미치지 않아서 머신러닝때 drop했습니다.
2.1.2. 변수별 그래프(2019)
-당월 매출 금액
-당월 매출 건수
-점포 수
-개업 점포 수
-총 유동인구 수
-총 상주인구 수
-총 직장인구 수
-아파트 단지 수
-집객시설 수
2.1.3. 변수별 그래프(2020)
-당월 매출 금액
-당월 매출 건수
-점포 수
-개업 점포 수
-총 유동인구 수
-총 상주인구 수
-총 직장인구 수
-아파트 단지 수
-집객시설 수
2.2. 업종 통합(장정윤)
2.2.1. 변수별 그래프(2019)
-당월 매출 금액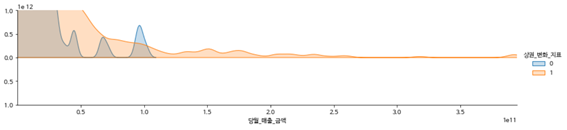
-당월 매출 건수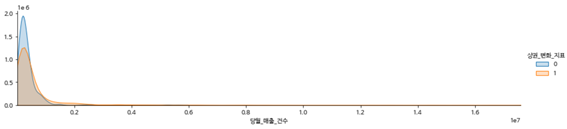
-점포 수
-개업 점포 수
-총 유동인구 수
-총 직장인구 수
-아파트 단지 수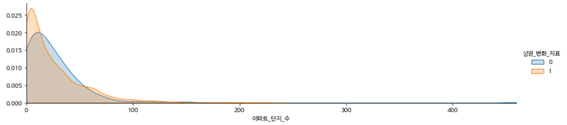
-집객시설 수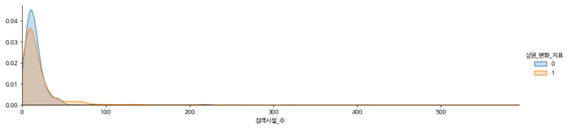
2.2.2. 변수별 그래프(2020)
-당월 매출 금액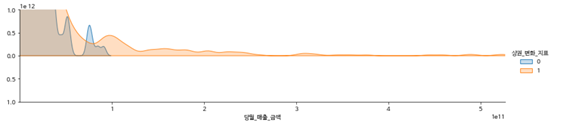
-당월 매출 건수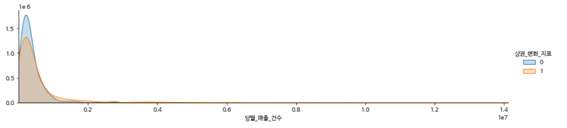
-점포 수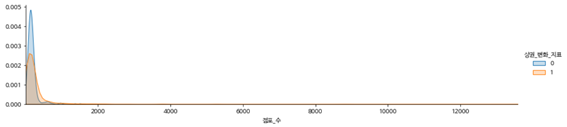
-개업 점포 수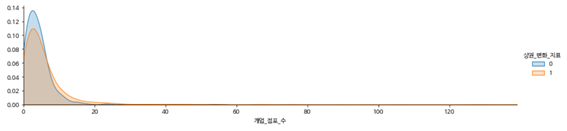
-총 유동인구 수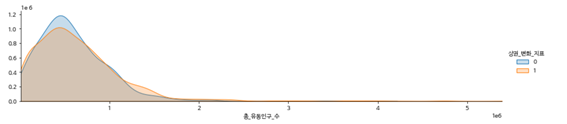
-총 직장인구 수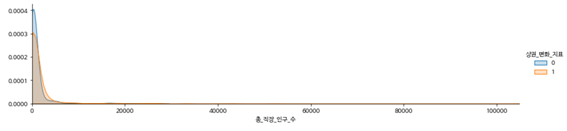
-아파트 단지 수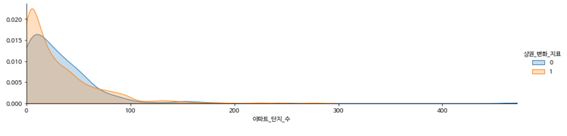
-집객시설 수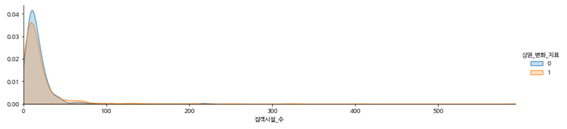
3. 머신러닝
전처리한 데이터를 바탕으로 kNN, Decision Tree, Random Forest, Navie Bayes, Support Vector Machine을 돌려 가장 정답률이 높은 두 개의 결과를 시각화, 분석해보았다. train dataset과 test dataset의 비율은 7:3으로 하며 비복원 추출을 하고, 트리가 복잡할수록 오버피팅이 일어날 확률이 증가하므로 max_depth을 조정하여 Pruning한다.
Python의 scikit-learn 라이브러리를 사용하였다.
3.1. 업종 분류(김가영)
3.1.1. 머신러닝 알고리즘별 정답률
-코로나 이전(2019)
| Algorithm | accuracy | Rank |
|---|---|---|
| kNN | 80.92% | 4 |
| Deicision Tree | 81.64% | 1 |
| Random Forest | 81.42% | 2 |
| Navie Bayes | 75.23% | 5 |
| Support Vector Machine | 81.34% | 3 |
-코로나 이후(2020)
| Algorithm | accuracy | Rank |
|---|---|---|
| kNN | 80.94% | 4 |
| Deicision Tree | 82.00% | 1 |
| Random Forest | 81.48% | 2 |
| Navie Bayes | 33.74% | 5 |
| Support Vector Machine | 81.39% | 3 |
3.1.2. 머신러닝 결과 해석
-코로나 이전(2019)
- 집객시설 수(Deicision Tree)
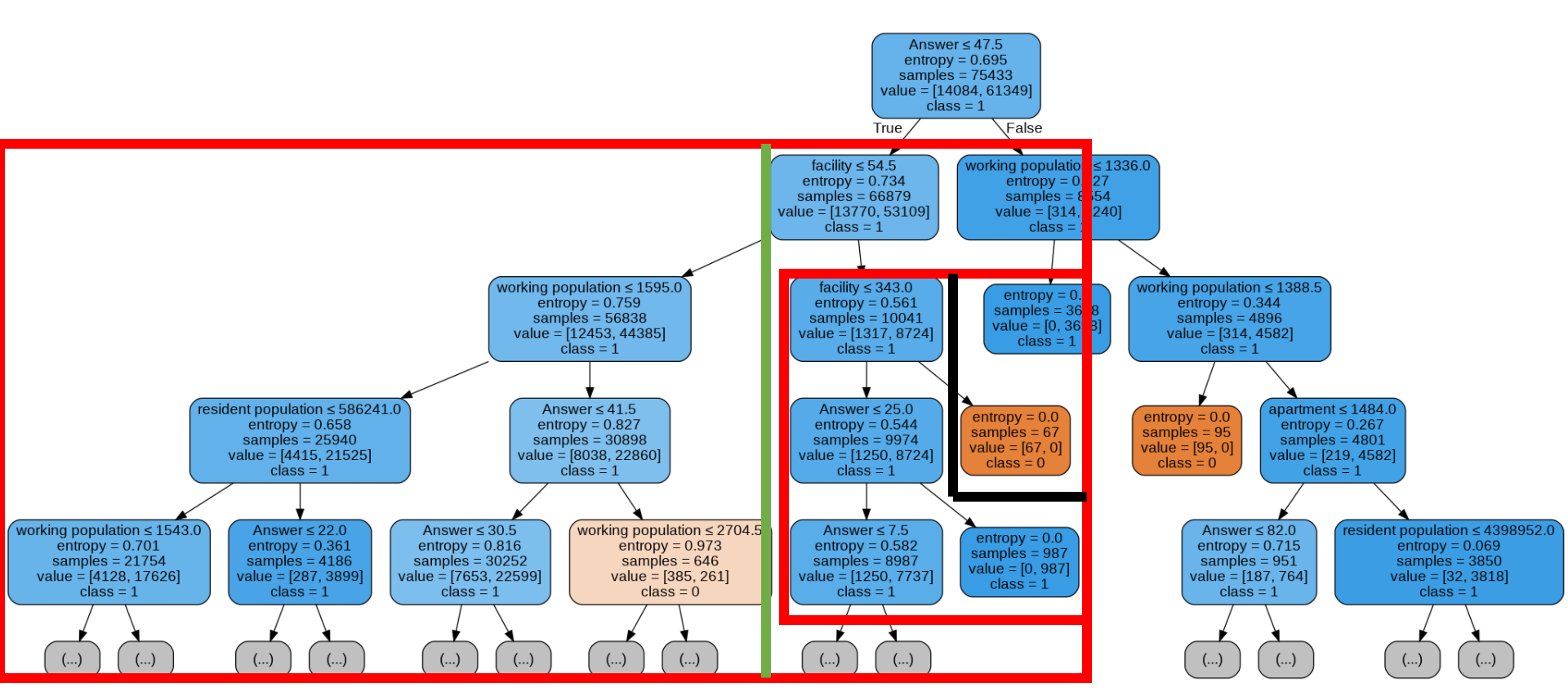
큰 네모에서 초록색선을 기준으로 왼쪽은 집객시설 수가 상대적으로 적으며, 오른쪽은 상대적으로 많다. 채도가 명확하게 비교되지 않으므로 집객시설 수는 결과에 큰 영향을 미치지 않는다. 그러나 작은 네모에서는 검은색 선의 오른쪽이 집객시설이 월등히 많은 부분인데, 그 부분은 높은 성공률을 보였다.
- 총 직장인구 수(Random Forest)
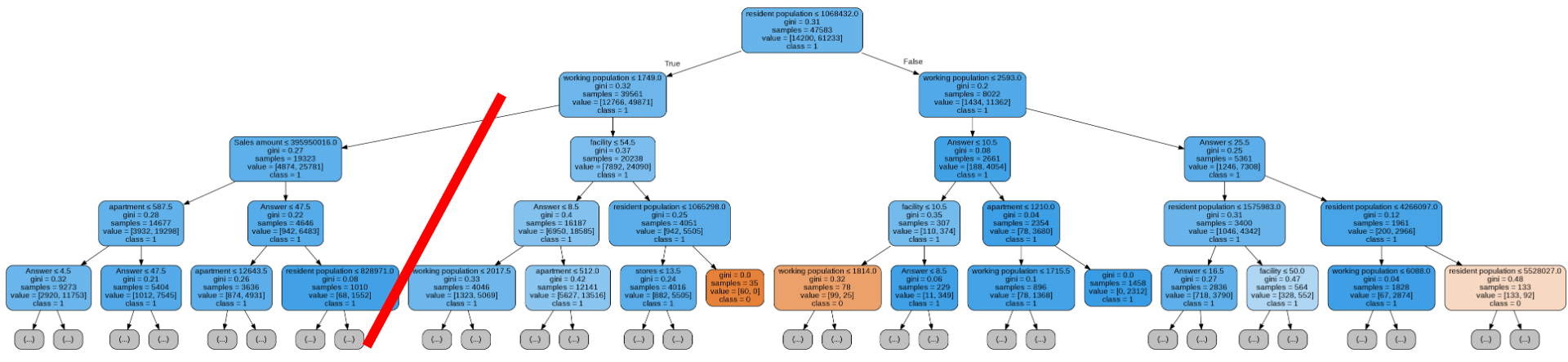
그림의 선을 기준으로 왼쪽은 직장인구수가 적고, 오른쪽은 많다. 채도를 비교했을 때 왼쪽이 오른쪽보다 파란색에 더 가까운 것을 보아 직장인구수가 많을수록 성공확률이 올라감을 알 수 있다. .
- 총 상주인구 수(Random Forest)
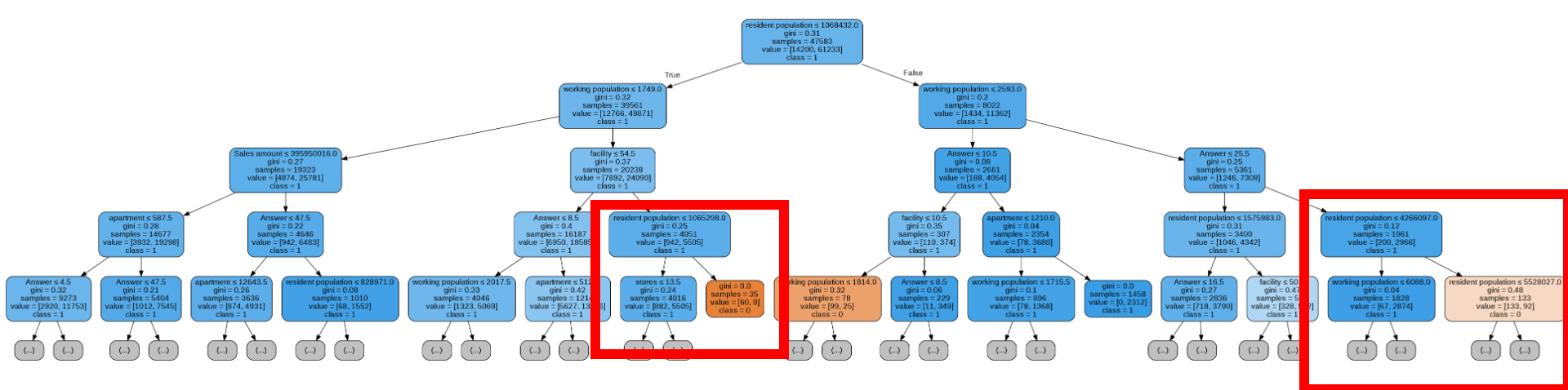
그림의 네모에서 좌측은 상주인구가 적고 오른쪽은 많다. 두 네모 모두 오른쪽이 주황색을 나타냈으므로 상주인구 수가 많을수록 성공확률이 높음을 알 수 있다.
- 총 아파트 단지 수(Random Forest)
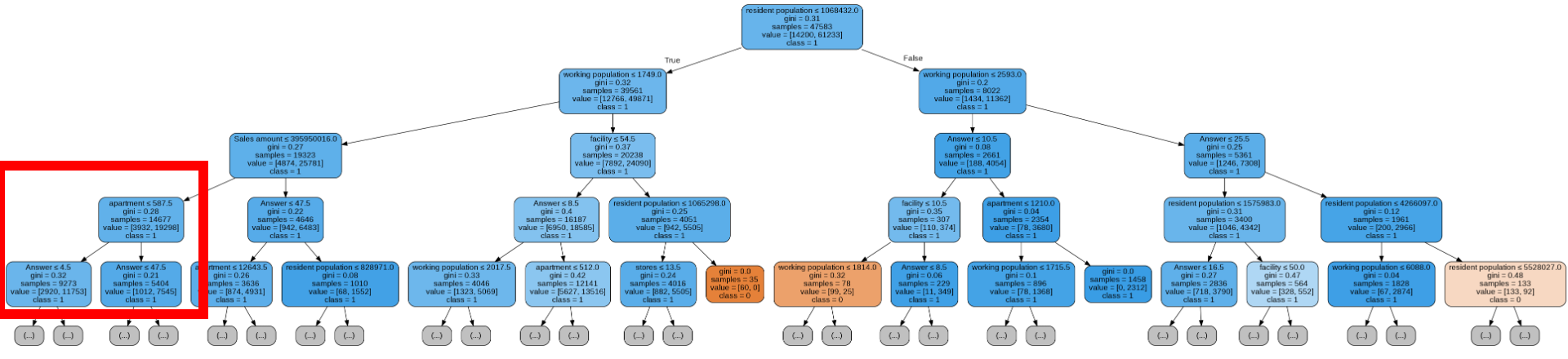
그림의 네모를 통해 아파트 수는 결과에 거의 영향을 미치지 않음을 알 수 있다.
-코로나 이후(2020)
- 집객시설 수(Deicision Tree)
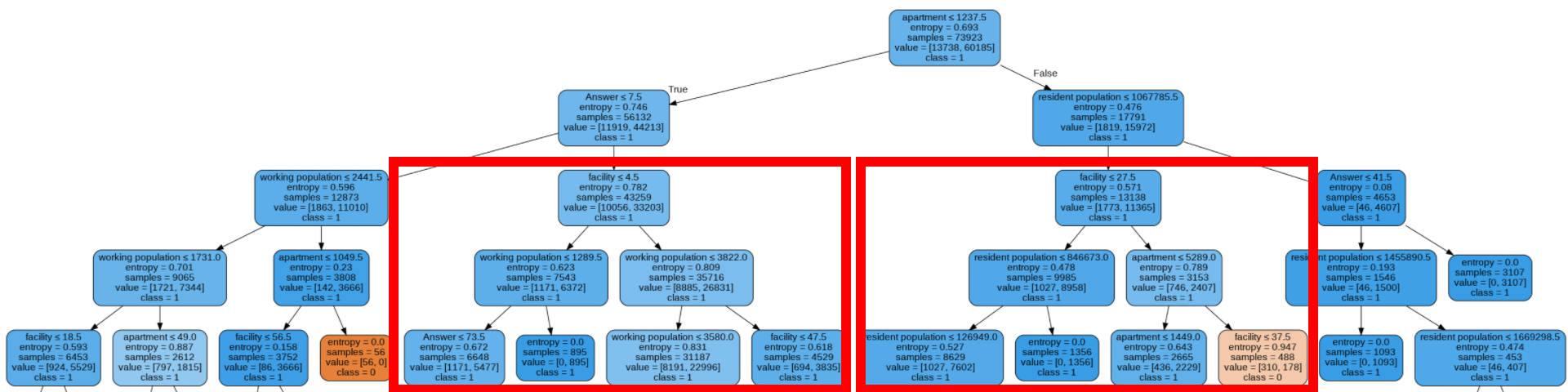
두 네모 중 왼쪽의 네모가 오른쪽보다 집객시설수가 적은데, 채도를 비교했을때 오른쪽이 더 주황색에 가까운 것을 알 수 있다. 따라서 집객시설수가 클수록 성공확률이 올라감을 알수있다.
- 총 직장인구 수(Random Forest)
직장인구 수가 높을 때 더 높은 성공률을 보인다는 것을 알 수 있다.
- 총 상주인구 수(Random Forest)
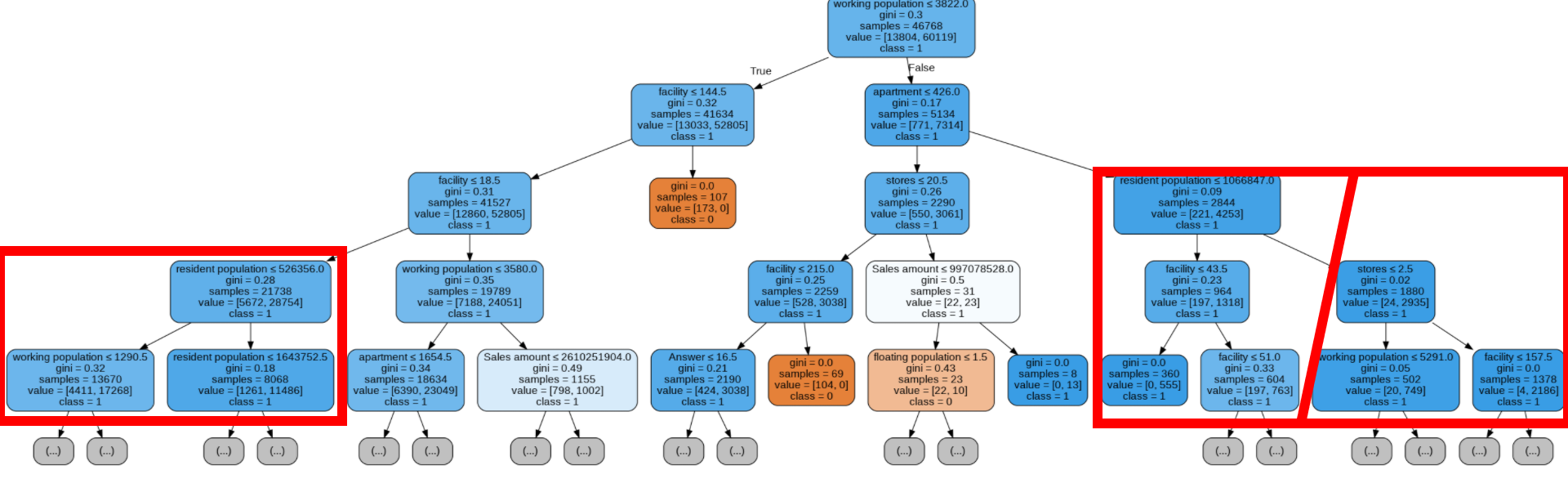
네모 안에 왼쪽은 상주인구 수가 상대적으로 적은것이고 오른쪽은 많은 것이다. 채도를 비교했을 때 상주인구 수가 많을 때 성공할 확률이 올라감을 알 수 있다.
- 아파트 단지 수(Deicision Tree)
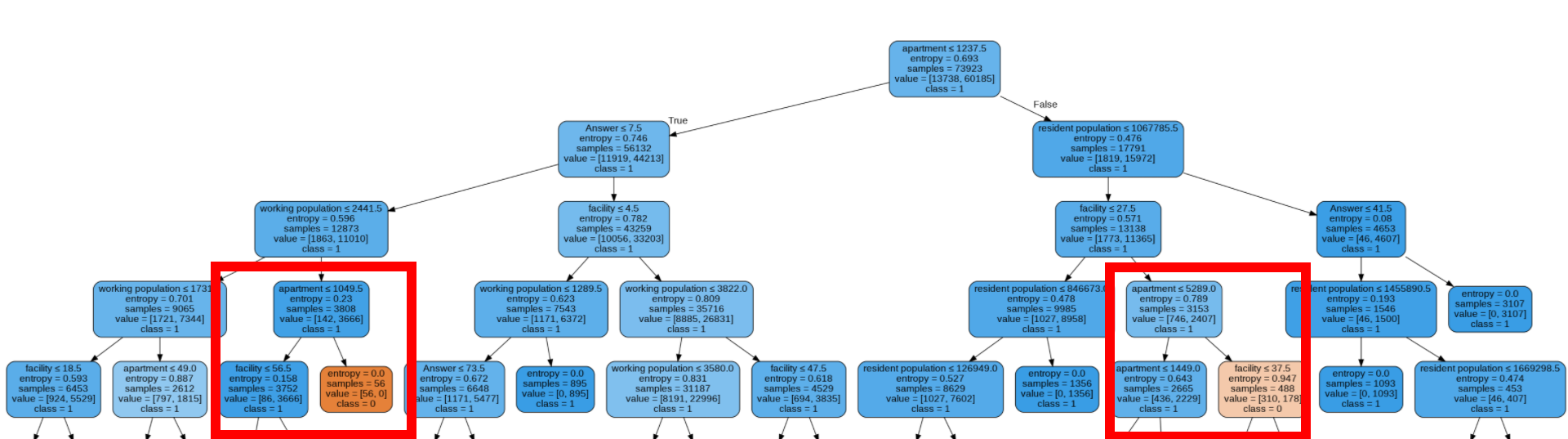
아파트 단지수가 클 때 더 높은 성공률을 보였다.
3.2. 업종 통합(장정윤)
3.2.1. 머신러닝 알고리즘별 정답률
-코로나 이전(2019)
| Algorithm | accuracy | Rank |
|---|---|---|
| kNN | 77.33% | 4 |
| Deicision Tree | 81.94% | 1 |
| Random Forest | 82.27% | 2 |
| Navie Bayes | 28.64% | 5 |
| Support Vector Machine | 82.23% | 3 |
-코로나 이후(2020)
| Algorithm | accuracy | Rank |
|---|---|---|
| kNN | 77.07% | 4 |
| Deicision Tree | 81.72% | 3 |
| Random Forest | 81.98% | 2 |
| Navie Bayes | 26.78% | 5 |
| Support Vector Machine | 82.07% | 1 |
3.2.2. 머신러닝 결과 해석
-코로나 이전(2019)
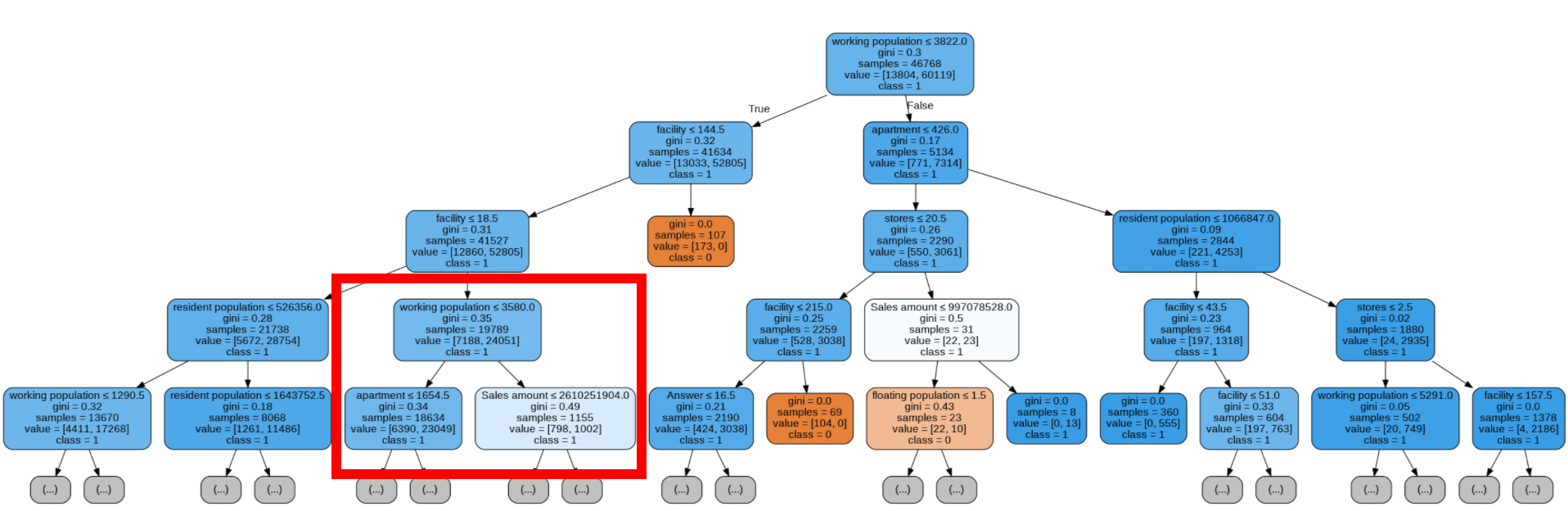
- Decision Tree
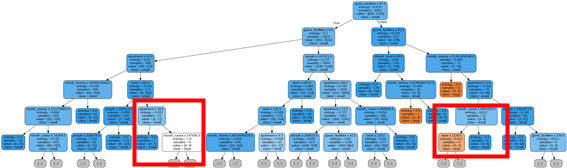
- 왼쪽 네모를 보면, 아파트 수가 많을수록 성공 비율이 높아짐을 볼 수 있 다.
- 오른쪽 네모를 보면 당월 매출 건수가 적을수록 성공 비율이 높아짐을 볼 수 있다.
- Random Forest
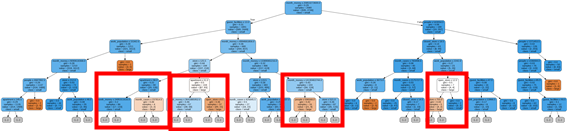
- 왼쪽 두 네모는 아파트 수가 많을수록 성공 확률이 높다는 것을 볼 수 있다.
- 오른쪽에서 두 번째에 위치한 네모는 당월매출금액이 적을수록 성공한다는 것을 예측할 수 있다.
- 제일 오른쪽 네모는 개업점포수가 적을수록 성공한다는 것을 예측할 수 있다.
-코로나 이후(2020)
- Decision Tree
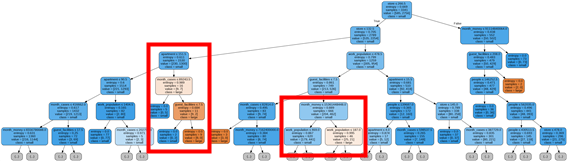
- 왼쪽 네모를 보면, 아파트 수가 많고 당월매출건수가 많고 집객시설수가 많을수록 성공 비율이 높아진다는 것을 볼 수 있다.
- 오른쪽 네모를 보면, 당월 매출 금액이 많을수록 성공 비율이 높아지는 것을 볼 수 있다.
- Random Forest

- 왼쪽 두 네모는 아파트 수가 많을수록 성공 확률이 높다는 것을 볼 수 있다.
- 오른쪽에서 두 번째에 위치한 네모는 당월매출금액이 적을수록 성공한다는 것을 예측할 수 있다.
- 제일 오른쪽 네모는 개업점포수가 적을수록 성공한다는 것을 예측할 수 있다.
4. 결론
4.1. 업종 분류(김가영)
2020년과 2019년에 공통적으로 집객시설 수와 총 상주인구 수, 총 직장인구 수가 많은수록 성공 확률이 높아진다는 결과를 도출하였다. 차이점은 아파트 수인데 2019년에는 아파트 수와 성공 확률이 반비례(DecisionTree)하거나 영향없음(RandomForest)이었는데 2020년에는 정비례하였다.
코로나 상황으로 배달 음식이 성행하면서 아파트 단지의 영향이 상대적으로 커진 것으로 추측된다. 이처럼 코로나 발생 이후 변화를 추측해볼 수 있어서 유의미했다.
그러나 서울 전체를 대상으로 진행했기 때문에, 특정 상권의 변화에 대해서는 알 수 없었다. 이 때문에 2019년과 2020년의 변화가 뚜렷하게 나타나지 못했다고 추측한다. 또한 2019년도에는 전년도대비 폐업률이 매우 높았던 해이기 때문에 2019년과 2020년으로 비교하는 것은 적절하지 못할 위험이 있다. 변수에서도 아쉬움이 있었는데 공실률, 폐업률 등 상권의 변화를 보여주는 다른 지표를 사용하지 못해 아쉬웠다. 그럼에도 여러 납득이 가능한 결과를 많이 도출했기 때문에 유의미한 활동이었다고 생각한다.
4.2. 업종 통합(장정윤)
2020년, 2019년 공통적으로 아파트 수가 많을수록 개업 점포수가 적을수록 성공 비율이 높아짐을 볼 수 있고, 2020년은 2019년과 달리 당월매출금액이 많을수록 성공 비율이 높아지는 것을 볼 수 있었다.
2019년과 2020년은 각각 코로나 발생 전과 코로나 발생 후이다. 코로나 발생 이후인 2020년에는 상권이 2019년보다 악화될 것을 예상했지만, 이 변수들만으로는 비교할 수가 없음을 판단했다. 폐업률, 임대료 변화 등 상권에 직간접적인 영향을 끼칠 요소를 반영하지 못해 아쉬움이 있었다. 또한, 구체적으로 예를 들어, 계절별로, 혹은 서비스 업종별로 분석하지 못해 구체적으로 결과를 분석할 수 없다는 점이 아쉬웠다.
5. 사용 데이터 셋
- 서울열린데이터광장
- 서울시우리마을가게상권분석서비스(상권-추정유동인구)
- 서울시우리마을가게상권분석서비스(상권-집객시설)
- 서울시우리마을가게상권분석서비스(상권-상주인구)
- 서울시우리마을가게상권분석서비스(상권-상권변화지표)
- 서울시우리마을가게상권분석서비스(상권-추정매출)
- 서울시우리마을가게상권분석서비스(상권-직장인구)
- 서울시우리마을가게상권분석서비스(상권-아파트)
- 서울시우리마을가게상권분석서비스(상권-점포)